- Что такое EVM
- Зачем нужна EVM
- Что делает пустой смарт-контракт с EVM
Полный список статей по теме тут.
Заходите в наш телеграмм канал — Blockchain Witnesses! Делитесь опытом или задавайте вопросы, если что-то непонятно.
Что такое EVM и зачем оно надо?
Хорошо, мы можем написать под каждый компьютер транслятор solidity в ассемблер. Ведь это так и так придется сделать.
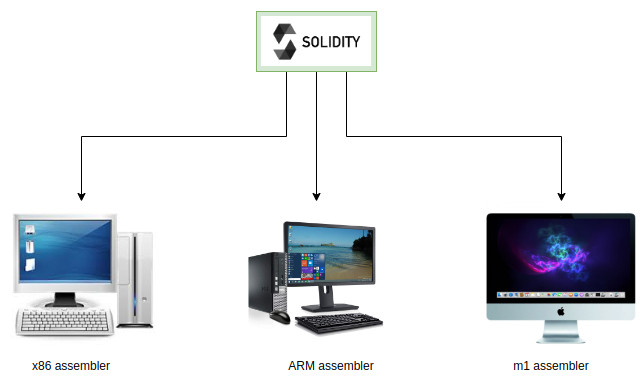
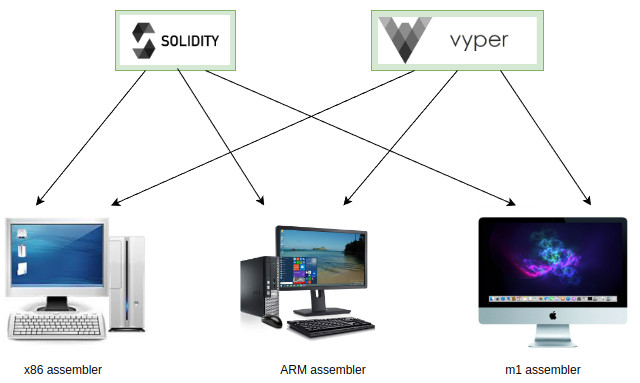
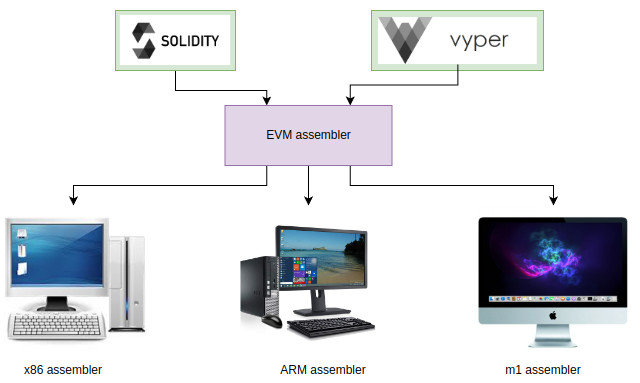
Искушенный читатель может спросить: «A как же регистры?». Регистров, которыми бы можно было явно управлять нет. И тем не менее можно сказать, что есть указатель на текущую инструкцию — pc, на вершину стэка. Однако, в явном виде инструкций для работы с ними нету.
Процессор исполняет инструкции, которые меняют стэк и память. А инструкции ассемблера примитивны. А оттого и непривычны.
В высокоуровневых языках программирования мы привыкли, что функции принимают аргументы и возвращают значения. И записываются они примерно так:
result = function(argument1, argument2)
Мы не задумываемся, где хранятся аргументы во время передачи функции и где хранится результат.
В ассемблере EVM аргументы для инструкций в основном передаются через стэк. Результат работы инструкции, если он есть, тоже записывается в стэк. Все делается через стэк. Т.е. если мы хотим выполнить инструкцию нам нужно:
- Положить аргументы в стэк
- Вызвать инструкцию
- Инструкция заберет аргументы из стэка
- Положит результат в стэк
- Теперь мы можем забрать результат из стэка
Важно: инструкции именно забирают аргументы из стэка. Т.е. читают и удаляют.
Чтобы было более понятно, давайте рассмотрим пример.
Пример выполнения инструкции
Давайте попробуем сложить два числа 1 и 2. Для этого нам понадобятся две инструкции:
| Инструкция | Что делает | Что должно быть в стэке | Что будет в стэке |
| PUSH1 X | кладет в стэк X | X | |
| ADD | складывает два значения из стэка | A, B | A + B |
Алгоритм работы будет такой:
- Кладем первый аргумент в стэк
- Кладем второй аргумент в стэк
- Выполняем сложение
|
1 2 3 |
PUSH1 01 PUSH1 02 ADD |
После выполнения этих инструкций на вершине стэка у нас будет результат сложения — 3.
Что делает пустой смарт-контракт
Мы, как разработчики Solidity, привыкли, что смарт-контракт просто загружается в блокчейн, и , может быть, выполняется конструктор. Однако, эта простая загрузка в блокчейн на самом деле довольно таки интересный процесс. И мы на него сейчас посмотрим.
Для этого сделаем простой смарт-контракт:
|
1 2 3 4 5 6 7 8 9 10 |
// SPDX-License-Identifier: GPL-3.0 pragma solidity ^0.8.25; contract BlockwitEmptyContract { } |
Скомпилируем его, скажем в Remix и скопируем байт-код. Для этого в разделе компилятора, нажмем на кнопочку — compile. А затем на кнопочку bytecode.
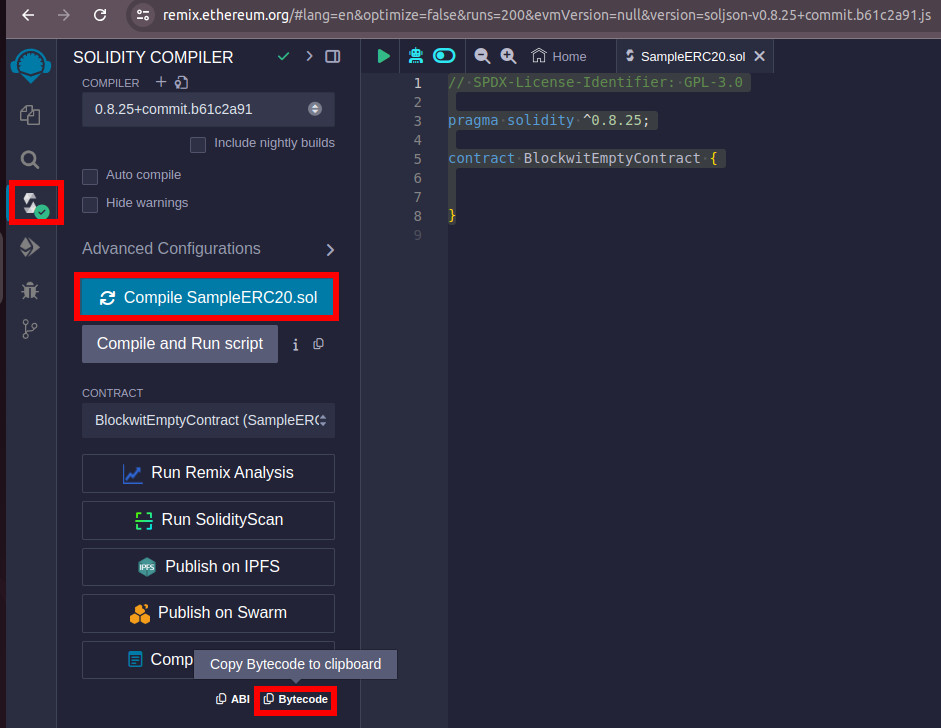
На самом деле декомпиляторы немного туповатые и расшифровывают байткод в лоб. Т.е. они не задумываются, что какая-то часть байт-кода может быть просто данными.
Забегая вперед, скажу что последняя байт байткода — это так называемые auxularity данные. Данные, в которых содержится вспомогательная мета-информация. Например — версия solidity, hash. И так далее.
6080604052348015600e575f80fd5b50603e80601a5f395ff3fe60806040525f80fdfe
На самом деле, как таковой структуры байткода нет. Просто перед метаданными стоит инструкция выхода из программы. Поэтому метаданные никогда не выполняются процессором.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
0000 60 PUSH1 0x80 0002 60 PUSH1 0x40 0004 52 MSTORE 0005 34 CALLVALUE 0006 80 DUP1 0007 15 ISZERO 0008 60 PUSH1 0x0e 000A 57 JUMPI 000B 5F PUSH0 000C 80 DUP1 000D FD REVERT label_000E: 000E 5B JUMPDEST 000F 50 POP 0010 60 PUSH1 0x3e 0012 80 DUP1 0013 60 PUSH1 0x1a 0015 5F PUSH0 0016 39 CODECOPY 0017 5F PUSH0 0018 F3 RETURN 0019 FE ASSERT 001A 60 PUSH1 0x80 001C 60 PUSH1 0x40 001E 52 MSTORE 001F 5F PUSH0 0020 80 DUP1 0021 FD REVERT 0022 FE ASSERT |
На самом деле, некоторые инструкции декомпилятор не распознает. Поэтому, идем на уже известный нам сайт с опкодами и редактируем вывод декомпилятора. Я еще поубирал ненужные комментарии.
Итак, давайте начнем разбирать.
MSTORE — инструкция, которая по адресу, который записан в первом аргументе стэка записывает значение второго аргумента стэка. У нас в стэке лежат 0x80, 0x040. Т.е. MSTORE запишет 0x80 в паять по адресу 0x40. Зачем это нужно?
| 0x0000 | зарезервировано (используется для методов хэширования) |
| 0x0020 | зарезервировано (используется для методов хэширования) |
| 0x0040 | указатель на первый свободный слот памяти |
| 0x0060 | зарезервировано |
| 0x0080 | отсюда начинается свободная память |
| …. | …. |
В документации описано тут.
|
1 2 3 |
0000 60 PUSH1 0x80 0002 60 PUSH1 0x40 0004 52 MSTORE |
Идем дальше:
|
1 |
0005 34 CALLVALUE |
|
1 |
0006 80 DUP1 |
Дублирует значение на стэке.
|
1 |
0007 15 ISZERO |
Помещает на стэк единицу, если предыдущее значение в стэке равно нулю. Таким образом проверяем, передан эфир во время загрузки контракта или нет.
|
1 |
0008 60 PUSH1 0x0e |
|
1 |
000A 57 JUMPI |
Прыгаем в адрес на стэке — т.е. на 0x0e, если второе значние в стэке 1 — т.е. мы идем на 0x0e, если в контракт передали 0 эфира.
|
1 |
000B 5f PUSH0 |
|
1 |
000C 80 DUP1 |
Клонирует последнее значение в стэке.
|
1 |
000D fd REVERT |
|
1 |
000E 5B JUMPDEST |
|
1 2 3 4 5 6 |
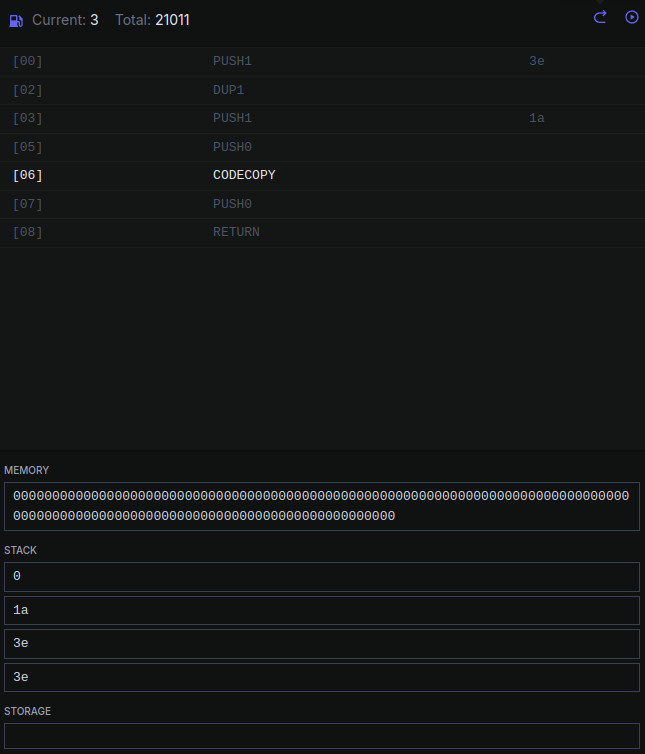
000F 50 POP // удаляем значение из стэка 0010 60 PUSH1 0x3e // помещаем значение 0x3e в стэк 0012 80 DUP1 // дублируем значение на стэке. 0013 60 PUSH1 0x1a // помещаем 0x1a на стэк 0015 5F PUSH0 // помещаем 0 на стэк. 0016 39 CODECOPY // копирует код в исполнительную область. |
Аргументы по стэку для CODECOPY:
| адрес, куда копировать |
| адрес, откуда копировать |
| размер копируемых данных |
В нашем случае копируется код размером 0x3e, начиная с 0x1a в 0. Т.е. будет скопирован код контракта и метаданные. Дальше мы увидим, какой код копируется.
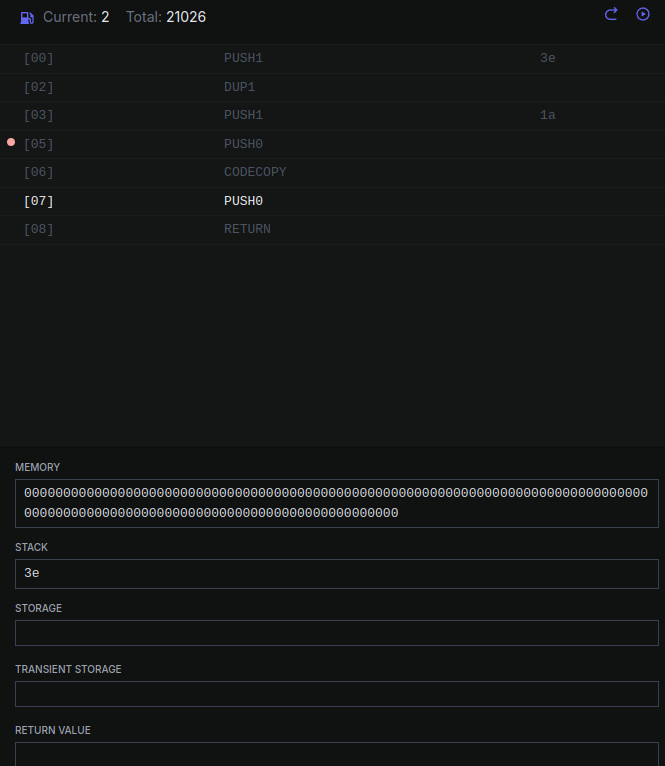
А сейчас идут инструкции для выхода из программы.
|
1 |
0017 5F PUSH0 |
|
1 |
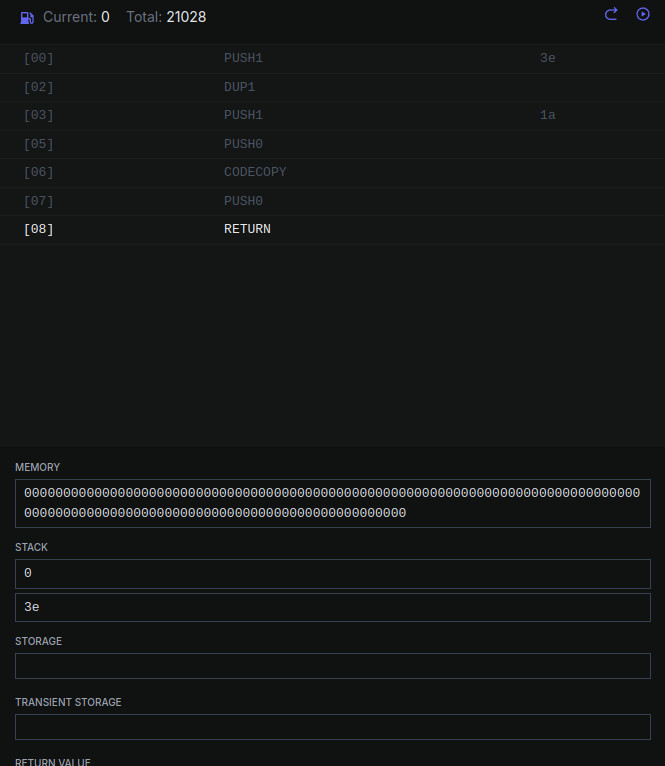
0018 F3 RETURN |
Выходим из программы, возвращая данные по адресу в стэке с размером стэке.
Мы помним, что в строке 0010 мы положили 0x3e. А затем зачем-то продублировали эти данные инструкцией DUP1. Давайте поместим этот кусок байткода в EVM отладчик и посмотрим, что будет до выполнения команд с адреса 0010.
Сначала стэк пустой.
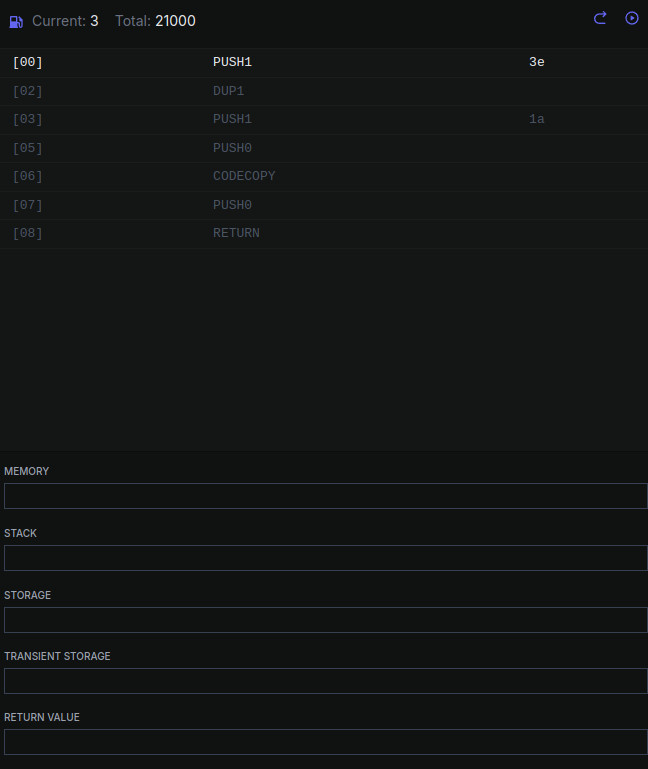
Последняя команда:
|
1 |
0019 FE ASSERT |
|
1 2 3 |
001A 60 PUSH1 0x80 001C 60 PUSH1 0x40 001E 52 MSTORE |
|
1 2 3 |
001F 5F PUSH0 0020 80 DUP1 0021 FD REVERT // выполнили выход. |
- Почему после PUSH0 идет DUP1 а не тот же PUSH0 ведь результат будет тот же. Программы, которые транслируют Solidiy в байткод достаточно прямолинейны. И какие-то блоки инструкций написаны в общем виде. И это, повод для низкоуровневой оптимизации. Чем мы и займемся в следующих статьях. Например, как мы знаем, каждая команда имеет свою стоимость. Например инструкция PUSH0 (2 единицы газа) стоит дешевле инструкции DUP1 (3 единицы газа). Поэтому замена DUP1 на PUSH0 сэкономит нам единицу газа.
- Мы встретили две команды выхода из программы REVERT и RETURN. И обе возвращают данные. В чем же разница? REVERT отменяет все изменения контракта, которые были сделаны в storage. Как правило, эту инструкцию применяют когда произошла какая-то ошибка в контракте.
- Инициализирует указатель свободной памяти
- Проверяет, передавался ли эфир
- Если эфир передавался, то выходим с ошибкой, если нет, то прыгаем на следующий участок кода.
- Копируем эффектиный код контракта и метаданные в память по нулевому адресу.
- Возвращаем скопированные данные в блокчейн — эти данные запишутся в блокчейн.
- Поскольку контракт у нас пустой, то скопированный код просто проинициализирует указатель свободной памяти и выйдет.
Первые 4 пункта и есть выполнение конструктора контракта. Единожды выполненный код конструктора больше не требуется, поэтому в блокчейн возвращается код контракта без конструктора.
Резюме
В этой статье мы познакомились в EVM и основными инструкциями. Разобрались, как смарт-контракт загружается в блокчейн.
Полный список статей по теме тут.
Заходите в наш телеграмм канал — Blockchain Witnesses! Делитесь опытом или задавайте вопросы, если что-то непонятно.

