В предыдущей статье мы разобрались, как передавать аргументы функции на примере простых типов. Давайте теперь напишем смарт-контракт, который хранит и устанавливает балансы.
Полный список статей по теме тут.
Заходите в наш телеграмм канал — Blockchain Witnesses! Делитесь опытом или задавайте вопросы, если что-то непонятно.
Контракт на Solidity
Если бы мы писали контракт на Solidity, то он выглядел бы так:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
// SPDX-License-Identifier: GPL-3.0 pragma solidity ^0.8.25; contract BlockwitBalancesContract { mapping(address => uint) public balances; function getBalance(address account) view public returns( uint) { return balances[account]; } function setBalance(address account, uint amount) public { balances[account] = amount; } } |
Мы уже знаем как работает селектор методов (см. вторую статью), а значит можем добавить в выбор новые методы. Мы также умеем читать и писать данные в маппинг. А в предыдущей статье научились передавать аргументы.
Метод записи баланса на ассемблере
- Прочитать размер из msg.data
1CALLDATASIZE - Вычислить размер аргументов. А это у нас размер msg.data минус 4 байта (идентификатор функции).
msg.data выглядит примерно так:4 байта — идентификатор метода 32 байта — адрес 32 байта — баланс 123PUSH1 0x04SWAP1SUBТеперь в стэке размер всех аргументов.
- Проверить, что размер аргументов равен 0x40. У нас два аргумента по 32 байта: адрес и сам баланс.
12345PUSH1 0x40EQISZEROPUSH1 revertJMPI
Если размер аргументов не равен 0x40, то мы прыгаем на revert. Это условное обозначение метки, мы пропишем в конце ее код.
- Загрузить в стэк первый аргумент — адрес
12PUSH1 0x04CALLDATALOAD
- Вычислить адрес в маппинге (см.статью 4 — хранения маппинга). Для этого грузим в память по адресу 0x0 адрес маркера маппинга. У нас будет 0x0. И грузим также сам адрес. Все это для вычисления хэша. Помним, что в стэке у нас уже есть адрес. После загрузки данных в область памяти для работы с хэшами, вызываем KECCAK256 для вычисления хэша. И стэке у нас окажется хэш — т.е. адрес по которому мы будем писать значение маппинга.
12345678PUSH0MSTOREPUSH0PUSH1 0x20MSTOREPUSH1 0x40PUSH0KECCAK256
- Загрузить в память баланс. Мы вычислили адрес, по которому записывать значение. Сейчас этот адрес в стэке. Теперь нам нужно загрузить в стэке само значение из msg.data, чтобы потом записать его в storage. Помним, что наше значение — баланс — это второй аргумент. А значит он будет в msg.data по смещению: (идентификатор функции) 0x04 + (адрес) 0x20 = 0x24.
12PUSH1 0x24CALLDATALOAD
- Записать в маппинг баланс по вычисленному адресу. На текущий момент в стэке у нас находятся
Второй аргумент — значение баланса Адрес, куда записывать значение в storage для маппинга … Остается только записать в storage наш баланс.
12SWAP1SSTORE - Теперь можем выходить из контракта.
123PUSH0DUP1RETURN
- Теперь добавим код выхода из программы, если у нас не верное кол-во аргументов:
12345revert:JUMPDESTPUSH0DUP1REVERT
Все, с методом записи мы разобрались.
Метод чтения баланса
Метод чтения баланса будет писать проще, потому что какие-то куски будут аналогичными как и в записи. Например — проверка размера аргумента. Или вычисление адреса для чтения из мэппинга. Итак, наш алгоритм:
- Читаем размер msg.data
1CALLDATASIZE - Вычисляем размер аргументов в msg.data. А это у нас размер msg.data минус 4 байта (идентификатор функции).
msg.data выглядит примерно так:4 байта — идентификатор метода 32 байта — адрес 123PUSH1 0x04SWAP1SUBТеперь в стэке размер всех аргументов.
- Проверим, что размер аргументов равен 0x20 — у нас один аргумент — адрес. И его размер всегда равен 0x20.
12345PUSH1 0x20EQISZEROPUSH1 revertJMPI
Когда мы писали метод записи, то уже написали код в котором происходит revert. Поэтому дублировать нет смысла.
- Теперь загрузим наш аргумент в стэк
12PUSH1 0x04CALLDATALOAD
- Вычисляем адрес, откуда будем читать. Комментировать не буду — код аналогичен, тому который мы написали в методе записи.
12345678PUSH0MSTOREPUSH0PUSH1 0x20MSTOREPUSH1 0x40PUSH0KECCAK256
- Загружаем значение из storage в стэк
1SLOAD
Теперь в стэке у нас значение баланса.
- Давайте теперь запишем в память наш баланс. Помним, что записывать нужно в свободную память. А указатель свободной памяти находится по адресу 0x40. Поэтому сначала чтаем указатель свободной памяти, дублируем его в стэке (потребуется когда будем возвращать данные RETURN’ом), а затем пишем в память наш баланс.
123456PUSH1 0x40MLOADDUP1SWAP2SWAP1MSTORE
Посмотрите внимательно на махинации со стэком, которые мы делаем дабы сохранить в стэке указатель на свободную память. Тут три команды: DUP1, SWAP2, SWAP1. Как упражнение вы можете сравнить этот способ каким-нибудь другим. Например, возможно просто прочитать указатель на свободную память в две команды будет дешевле по газу?
- Теперь можно выходить. На стэке у нас указатель свободной памяти. Осталось указать размер возвращаемых данных и выйти.
123PUSH1 0x20SWAP1RETURN
Добавляем селекторы функций:
Из чего состоит селектор функций и для чего он нужен, мы уже знаем из второй статьи. Давайте возьмем типовой код и расширим его нашими двумя функциями. Типовой код селектора:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
// проверка наличия 4-байтового идентификатора функции в msg.data JUMPDEST POP PUSH1 0x04 CALLDATASIZE LT PUSH1 revert JUMPI // загрузка 4-байтовго указателя в стэк PUSH0 CALLDATALOAD PUSH1 0xe0 SHR // тут начинаются блоки проверки функций DUP1 PUSH4 четырехбайтовый_идентификатор_функции EQ PUSH1 адрес_кода_функции JUMPI // выход, если что-то пошло не так revert: JUMPDEST PUSH0 DUP1 REVERT |
У нас две функции. Давайте вычислим их 4-байтовые идентификаторы c помощью этого сервиса. Т.е. вводим туда сигнатуры функции и забираем старшие 4 байта.
- getBalance(address) => f8b2cb4f3943230388faeee074f1503714bff212640051caba01411868d14ae3 => 0xf8b2cb4f
- setBalance(address,uint256) => e30443bc9bb3ffdc38bfb7be2087b5bd3bbaa5e972b5c0838e3741b6f1d20592 => 0xe30443bc
Мы можем заметить, что для вычисления идентификатора была использована сигнатура метода setBalance(address,uint256) . uint — это есть краткое название uint256. Компилятор при вызове будет использовать именно uint256.
А теперь заполним типовой код селектора в соответствие с нашими идентификаторами:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
// проверка наличия 4-байтового идентификатора функции в msg.data JUMPDEST POP PUSH1 0x04 CALLDATASIZE LT PUSH1 revert JUMPI // загрузка 4-байтовго указателя в стэк PUSH0 CALLDATALOAD PUSH1 0xe0 SHR // тут начинаются блоки проверки функций // Функция чтения баланса DUP1 PUSH4 0xf8b2cb4f EQ PUSH1 get_balance_code JUMPI // Функция записи баланса PUSH4 0xe30443bc EQ PUSH1 set_balance_code JUMPI // выход, если что-то пошло не так revert: JUMPDEST PUSH0 DUP1 REVERT |
Обратите внимание, что мы убрали DUP1 во втором блоке сравнения. Из второй статьи мы помним, что эта инструкция дублирует идентификатор функции из msg.size, чтобы он остался к следующему блоку сравнения. Компилятор создает код в лоб. Мы же ручками можем убрать эту инструкцию в последнем блоке сравнения, ибо она тут бессмысленна.
Собираем код контракта
Теперь у нас есть и типовые конструкции: конструктор, инициализация указателя на свободную память, проверка на наличие четырехбайтовго указателя.
И есть не типовые конструкции: блок функции записи, блок функции чтения, блоки селектора функций.
Выходит, теперь мы можем собрать наш код. Давайте сделаем это.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 |
// ============== КОНСТРУКТОР ================ // инициализация указателя на свободную память 0000 60 PUSH1 0x80 0002 60 PUSH1 0x40 0004 52 MSTORE // проверка на перечисление wei во время вызова 0005 34 CALLVALUE 0006 80 DUP1 0007 15 ISZERO 0008 60 PUSH1 0x0e 000A 57 JUMPI 000B 5F PUSH0 000C 80 DUP1 000D FD REVERT // копирование эффективного кода (без конструктора) в блокчейн 000E 5B JUMPDEST 000F 50 POP 0010 60 PUSH1 0x7b 0012 80 DUP1 0013 60 PUSH1 0x1a 0015 5F PUSH0 0016 39 CODECOPY 0017 5F PUSH0 0018 F3 RETURN 0019 FE ASSERT // ========== ЭФФЕКТИВНЫЙ КОД КОНТРАКТА ============= // инициализация указателя на свободную память 001A 60 PUSH1 0x80 001C 60 PUSH1 0x40 001E 52 MSTORE // проверка, что во время вызова не перечислились wei 001F 34 CALLVALUE 0020 80 DUP1 0021 15 ISZERO 0022 60 PUSH1 0x0e 0024 57 JUMPI 0025 5F PUSH0 0026 80 DUP1 0027 FD REVERT // ========== СЕЛЕКТОР МЕТОДОВ ====================== // проверка наличия 4-байтового идентификатора функции в msg.data 0028 5B JUMPDEST 0029 50 POP 002A 60 PUSH1 0x04 002C 36 CALLDATASIZE 002D 10 LT 002E 60 PUSH1 0x2f 0030 57 JUMPI // загрузка 4-байтового указателя в стэк 0031 5F PUSH0 0032 35 CALLDATALOAD 0033 60 PUSH1 0xe0 0035 1C SHR // тут начинаются блоки проверки функций // Функция чтения баланса 0036 80 DUP1 0037 63 PUSH4 0xf8b2cb4f 003C 14 EQ 003D 60 PUSH1 0x55 // get_balance_code 003F 57 JUMPI // Функция записи баланса 0040 63 PUSH4 0xe30443bc 0045 14 EQ 0046 60 PUSH1 0x33 //set_balance_code 0048 57 JUMPI // выход, если что-то пошло не так 0049 5B JUMPDEST 004A 5F PUSH0 004B 80 DUP1 004C FD REVERT // =========== КОД МЕТОДА ЗАПИСИ БАЛАНСА ============= // посчитаем размер аргументов 004D 5B JUMPDEST 004E 36 CALLDATASIZE 004F 60 PUSH1 0x04 0051 90 SWAP1 0052 03 SUB // проверяем что размер аргументов равен 0x40 0053 60 PUSH1 0x40 0055 14 EQ 0056 15 ISZERO 0057 60 PUSH1 0x2f 0059 57 JMPI // грузим в стэк первый аргумент - адрес 005A 60 PUSH1 0x04 005C 35 CALLDATALOAD // вычисляем куда в storage записывать значение баланса 005D 5F PUSH0 005E 52 MSTORE 005F 5F PUSH0 0060 60 PUSH1 0x20 0062 52 MSTORE 0063 60 PUSH1 0x40 0065 5F PUSH0 0066 20 KECCAK256 // загружаем баланс из msg.data в стэк 0067 60 PUSH1 0x24 0069 35 CALLDATALOAD // записываем баланс по вычисленному адресу мэппинга 006A 90 SWAP1 006B 55 SSTORE // выходим 006C 5F PUSH0 006D 80 DUP1 006E F3 RETURN // =========== КОД МЕТОДА ЧТЕНИЯ БАЛАНСА ============= // вычисляем размер аргументов 006F 5B JUMPDEST 0070 36 CALLDATASIZE 0071 60 PUSH1 0x04 0073 90 SWAP1 0074 03 SUB // проверяем что размер аргументов равен 0x20 0075 60 PUSH1 0x20 0077 14 EQ 0078 15 ISZERO 0079 60 PUSH1 0x2f 007B 57 JMPI // загрузим аргумент адрес - в стэк 007C 60 PUSH1 0x04 007E 35 CALLDATALOAD // вычисляем по адресу из стэка адрес, откуда из мэппинга будем читать 007F 5F PUSH0 0080 52 MSTORE 0081 5F PUSH0 0082 60 PUSH1 0x20 0084 52 MSTORE 0085 60 PUSH1 0x40 0087 5F PUSH0 0088 20 KECCAK256 // загружаем значение баланса из storage в стэк 0089 54 SLOAD // записываем баланс из стэка в память 008A 60 PUSH1 0x40 008C 51 MLOAD 008D 80 DUP1 008E 91 SWAP2 008F 90 SWAP1 0090 52 MSTORE // выходим, возвращая баланс 0091 60 PUSH1 0x20 0093 90 SWAP1 0094 F3 RETURN |
Проверка работоспособности
Мы написали много интересного кода, а теперь осталось только проверить. Давайте напишем тестовый проект на hardhat:
- Создаем папку проекта и переходим в нее
- Устанавливаем hardhat: npm install —save-dev hardhat
- Инициализируем проект: npx hardhat init
Выбираем typescript project - В папке contracts создаем файл с нашим контрактом BlockwitBalancesContract.sol:
1234567891011121314151617// SPDX-License-Identifier: GPL-3.0pragma solidity ^0.8.25;contract BlockwitBalancesContract {mapping(address => uint) public balances;function getBalance(address account) view public returns( uint) {return balances[account];}function setBalance(address account, uint amount) public {balances[account] = amount;}} - В папке test создаем файлик с нашими тестами BlockwitBalancesContract.ts:
123456789101112131415161718192021222324252627import {loadFixture,} from "@nomicfoundation/hardhat-toolbox/network-helpers";import {expect} from "chai";import hre from "hardhat";describe("BlockwitBalancesContract", function () {async function deploy() {const [owner, otherAccount] = await hre.ethers.getSigners();const BlockwitBalancesContract = await hre.ethers.getContractFactory("BlockwitBalancesContract");const blockwitBalancesContract = await BlockwitBalancesContract.deploy();return {blockwitBalancesContract, owner, otherAccount};}describe("SmokyTests", function () {it("Write and read balance", async function () {const {blockwitBalancesContract, owner, otherAccount} = await loadFixture(deploy);const balance = 777;await blockwitBalancesContract.setBalance(otherAccount, balance);expect(await blockwitBalancesContract.getBalance(otherAccount)).to.equal(balance);});});});
Это тест оригинального контракта. - В папке test создадим файлик с тестами не оптимизированного байткода BlockwitBalancesContractBytecodeNotOptimized.sol:
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768697071727374757677787980import {loadFixture,} from "@nomicfoundation/hardhat-toolbox/network-helpers";import {expect} from "chai";import hre from "hardhat";describe("BlockwitEmptyContractBytecodeNotOptimized", function () {async function deploy() {const [owner, otherAccount] = await hre.ethers.getSigners();const bytecode = "0x" +// constructor// - pointer to empty memory initialization"6080604052" +// - checks whether sent ether"348015600e575f80fd" +// - copy code to memory and return"5b506102b58061001c5f395ff3fe" +// smart-contract// - pointer to empty memory initialization"6080604052" +// - checks whether sent ether"34801561000f575f80fd" +// - checks whether it 4-bytes function identifier call or not"5b506004361061003f57" +// - methods selector// -- load 4-bytes identifier from msg.data"5f3560e01c" +// is balances(address) ?"8063" + "27e235e3" + "146100" + "43" + "57" +// is setBalance(address,uint256) ?"8063" + "e30443bc" + "146100" + "73" + "57" +// is getBalance(address) ?"8063" + "f8b2cb4f" + "146100" + "8f" + "57" +// - revert in case of eth sent or 4-bytes function selector not found"5b5f80fd" +// - functions code"5b61005d600480360381019061005891906101bb565b6100bf565b60405161006a91906101fe565b60405180910390f35b61008d60048036038101906100889190610241565b6100d3565b005b6100a960048036038101906100a491906101bb565b610118565b6040516100b691906101fe565b60405180910390f35b5f602052805f5260405f205f915090505481565b805f808473ffffffffffffffffffffffffffffffffffffffff1673ffffffffffffffffffffffffffffffffffffffff1681526020019081526020015f20819055505050565b5f805f8373ffffffffffffffffffffffffffffffffffffffff1673ffffffffffffffffffffffffffffffffffffffff1681526020019081526020015f20549050919050565b5f80fd5b5f73ffffffffffffffffffffffffffffffffffffffff82169050919050565b5f61018a82610161565b9050919050565b61019a81610180565b81146101a4575f80fd5b50565b5f813590506101b581610191565b92915050565b5f602082840312156101d0576101cf61015d565b5b5f6101dd848285016101a7565b91505092915050565b5f819050919050565b6101f8816101e6565b82525050565b5f6020820190506102115f8301846101ef565b92915050565b610220816101e6565b811461022a575f80fd5b50565b5f8135905061023b81610217565b92915050565b5f80604083850312156102575761025661015d565b5b5f610264858286016101a7565b92505060206102758582860161022d565b915050925092905056fe" +// metadata"a2646970667358221220" +"7b810610924a3e37878cfb5808a2dbf281ce1da8327dd4a672b13ccdfae4ab0f" +"64736f6c6343" +// - major version"0008" +// - minor version"19" +"0033";console.log(bytecode);console.log("Bytecode size: " + bytecode.length/2);const txReceipt = await owner.sendTransaction({data: bytecode})const txResult = await txReceipt.wait();if (txResult?.contractAddress == null)throw "Returned empty address";console.log("Gas used: " + txResult.gasUsed);const contractAddress = txResult.contractAddress;const BlockwitBalancesContract = await hre.ethers.getContractFactory("BlockwitBalancesContract");const blockwitBalancesContract = await BlockwitBalancesContract.attach(contractAddress);return {blockwitBalancesContract, owner, otherAccount};}describe("SmokyTests", function () {it("Write and read balance", async function () {const {blockwitBalancesContract, owner, otherAccount} = await loadFixture(deploy);const balance = 777;await blockwitBalancesContract.setBalance(otherAccount, balance);expect(await blockwitBalancesContract.getBalance(otherAccount)).to.equal(balance);});});}); - В папке test создадим файлик с тестами оптимизированного байткода BlockwitBalancesContractBytecodeOptimized.sol:
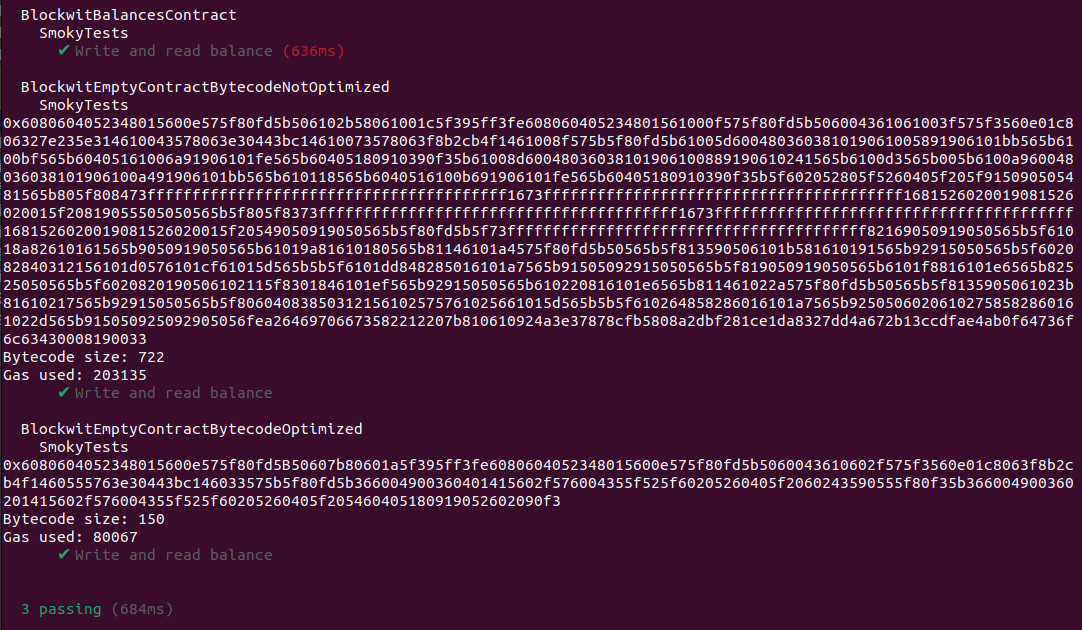
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112import {loadFixture,} from "@nomicfoundation/hardhat-toolbox/network-helpers";import {expect} from "chai";import hre from "hardhat";describe("BlockwitEmptyContractBytecodeOptimized", function () {async function deploy() {const [owner, otherAccount] = await hre.ethers.getSigners();const bytecode = "0x" +// constructor// - pointer to empty memory initialization"6080604052" +// - checks whether sent ether"348015600e575f80fd" +// - copy code to memory and return"5B50607b80601a5f395ff3fe" +// smart-contract// - pointer to empty memory initialization"6080604052" +// - checks whether sent ether"348015600e575f80fd" +// - checks whether it 4-bytes function identifier call or not"5b5060043610602f57" +// - methods selector// -- load 4-bytes identifier from msg.data"5f3560e01c" +// is getBalance(address) ?"8063" + "f8b2cb4f" + "1460" + "55" + "57" +// is setBalance(address,uint256) ?"63" + "e30443bc" + "1460" + "33" + "57" +// - revert in case of eth sent or 4-bytes function selector not found"5b5f80fd" +// - functions code// -- setBalance// --- read arguments size"5b3660049003" +// --- check size equals 0x40"60" + "40" + "141560" + "2f" + "57" +// --- read first argument from msg.data to stack"600435" +// --- calculate in where in storage write argument"5f525f60205260405f20" +// --- read balance from msg.data to stack"602435" +// --- write balance to calculated address in storage"9055" +// --- return"5f80f3" +// -- getBalance// --- read arguments size"5b3660049003" +// --- check size equals 0x20"60" + "20" + "141560" + "2f" + "57" +// --- read first argument from msg.data to stack"600435" +// --- calculate from where in storage going to read balance"5f525f60205260405f20" +// --- read balance from storage to stack"54" +// --- write balance from stack to memory"60405180919052" +// --- return with balance from memory"602090f3";/*// metadata"a2646970667358221220" +"7b810610924a3e37878cfb5808a2dbf281ce1da8327dd4a672b13ccdfae4ab0f" +"64736f6c6343" +// - major version"0008" +// - minor version"19" +"0033";*/console.log(bytecode);console.log("Bytecode size: " + bytecode.length/2);const txReceipt = await owner.sendTransaction({data: bytecode})const txResult = await txReceipt.wait();if (txResult?.contractAddress == null)throw "Returned empty address";console.log("Gas used: " + txResult.gasUsed);const contractAddress = txResult.contractAddress;const BlockwitBalancesContract = await hre.ethers.getContractFactory("BlockwitBalancesContract");const blockwitBalancesContract = await BlockwitBalancesContract.attach(contractAddress);return {blockwitBalancesContract, owner, otherAccount};}describe("SmokyTests", function () {it("Write and read balance", async function () {const {blockwitBalancesContract, owner, otherAccount} = await loadFixture(deploy);const balance = 777;await blockwitBalancesContract.setBalance(otherAccount, balance);expect(await blockwitBalancesContract.getBalance(otherAccount)).to.equal(balance);});});}); - Запускаем: npx hardhat test и должны получить успех. А один из тестов выведет байткод оптимизированного и не оптимизированного смарт-контрактов. А также размеры и стоимость по газу.
Готовы репозиторий можно склонировать отсюда — https://github.com/BlockWit/blockwit-balance-contract-field-optimization.
Резюме
Отлично! Мы написали свой первый полезный контракт на ассемблере. Давайте посмотрим газ и размер до и после:
| Размер | Газ | |
| До оптимизации | 722 | 203135 |
| После оптимизации | 150 | 80067 |
Выигрыш по размеру — почти в 5 раз. Выигрыш по газу — в 2 раза. На самом деле, это не очень объективные метрики. Дело в том, что в большинстве случаев контракты загружается один раз. Примеры постоянно создающихся контрактов — это пулы ликвидности.
Чаще всего у контрактов используются методы. А значит и оптимизации разумно выполнять с оглядкой на то, какие методы будут использоваться наиболее часто.
Возьмем, к примеру, контракт популярной монеты. Такой как USDT. Контракт загружен единожды. А перемещения балансов могут достигать тысячи транзакций в день. Тем не менее, существенной оптимизации таких методов достичь крайне сложно, а иногда практически невозможно. Почему? Если вы посмотрите на описание стоимости выполнения инструкций, то большинство инструкций сами по себе стоят дешево ~3 единицы газа. А вот инструкции работы с storage стоят в сотни и даже тысячи раз больше:
| SSTORE | 20 000 за единицу информации (зависит от ситуации) |
| SLOAD | 800 за единицу информации (зависит от ситуации) |
Т.е. оптимизации самого кода вносят крайне малый вклад, если вы используете инструкции работы со storage. А изменение состояния блокчейна — это и есть работа с инструкциями storage. Т.е. любой метод, который тарифицируется, использует инструкции работы со storage. Поэтому, существенной оптимизации можно достичь, оптимизируя логику работу со storage данными!
Давайте приведем более объективные метрики — вызов метода setBalance:
| До оптимизации | После оптимизации | |
| Первый вызов для одного адреса | 44 806 | 43 913 |
| Второй вызов для одного адреса | 27 306 | 26 813 |
Как видите, наши оптимизации дают экономию всего-лишь ~1%.
Но напомню, наша конечная цель не оптимизировать контракт по максимум, а изучить работу смарт-контрактов на уровне виртуально машины.
Наш контракт может хранить балансы и записывать балансы. Однако, запись балансов никак не защищена. Т.е. любой пользователь может менять балансы. В следующей статье мы этим и займемся.
Полный список статей по теме тут.
Заходите в наш телеграмм канал — Blockchain Witnesses! Делитесь опытом или задавайте вопросы, если что-то непонятно.
