В предыдущей статье мы оптимизировали контракт с одним полем. Это боле было типа unit. Тип uint можно считать примитивным. Он имеет конечную длину — 32 байта. Его легко записать и считать в storage. Однако, как мы знаем, в смарт-контракта встречаются и более сложные типы. Например, ассоциативный массив или mapping. И, чтобы уметь оптимизировать реальный смарт-контракты, нам потребуется понять, как работать c mapping. Для этого нам потребуется ответить на три вопроса:
- Как создавать mapping
- Как записывать
- Как считывать
Для того, чтобы разобраться во всем, мы возьмем маппинг простых типов. А именно: mapping(address -> uint).
Предыдущая статья. Следующая статья.
Полный список статей по теме тут.
Заходите в наш телеграмм канал — Blockchain Witnesses! Делитесь опытом или задавайте вопросы, если что-то непонятно.
Как в теории работает mapping
Каждый контракт в EVM имеет свой storage, который может адресовать до 2 в 256 слотов размером в 32 байта. Это невообразимо огромное пространство. Естественно, физически такого объема нет. EVM выделяется слоты по требованию. Если слот пустой, Solidity возвращает нули. Если вы попытаетесь что-то записать в пустой слот, то только тогда Solidity реально выделит физическую память. И только за это выделение вы заплатите газ.
Для любого маппинга Solidity обязывает делать пустой слот, так называемый маркер-слот. Мы просто запоминаем, что такой-то слот в storage у нас есть маркер слот для маппинга. Поскольку слот пустой, то физический EVM его не выделяет. А значит для создания mapping’а ничего записывать в storage не нужно. Зачем нужен этот маркер слот — мы узнаем чуть позже.
Как записать само значение в mapping? Очевидно, что значение нужно записать в слот storage. Но по какому адресу? Если Вы знакомы с устройством ассоциативных массивов в других языках, то догадаетесь, что к ключу применяется хэш-функция. В Solidity принята хэш-функция Keccak256. Т.е. разумно предположить, что запись в мэппинг происходит так:
- Вычисляем адрес слота: keccak256(key)
- По вычисленному адресу записываем значение
Представьте теперь, что у нас два маппинга:
|
1 2 3 |
mapping(address -> uint) first; mapping(address -> uint) second; |
И в оба маппинга мы пытаемся записать значение:
|
1 2 3 |
first[0xfd629caaDc426DaE4Fe97693741D106E75dbA09e] = 777; second[0xfd629caaDc426DaE4Fe97693741D106E75dbA09e] = 888; |
А поскольку ключ у нас один — 0xfd629caaDc426DaE4Fe97693741D106E75dbA09e, то в обоих случаях мы получим одинаковый хэш. А значит значения будет записано в один и тот же слот для обоих маппингов. И только последнее записанное значение будет актуальным.
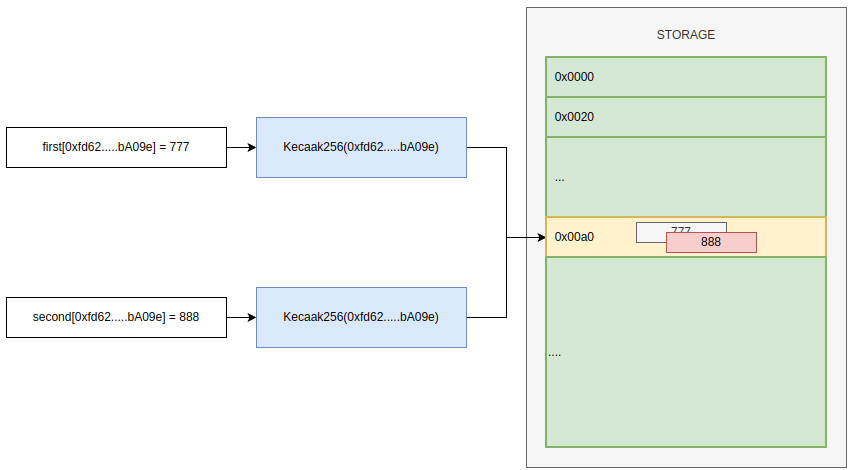
Выходит, что наше предположение о том, что для вычисления слота нам достаточно взять хэш от ключа не верно? Не совсем. Нам просто нужно добавить при вычисление ключа еще какое-нибудь значение. Это значение должно соответствовать как-то нашему маппингу. И быть для него уникальным. Помните, мы говорили выше про маркер-слот. При расчете хэша добавляем адрес маркер-слота к ключу:
Адрес слота для значения = keccak256(marker-slot-address + key)
Теперь адреса для значений у каждого маппинга будут уникальными.
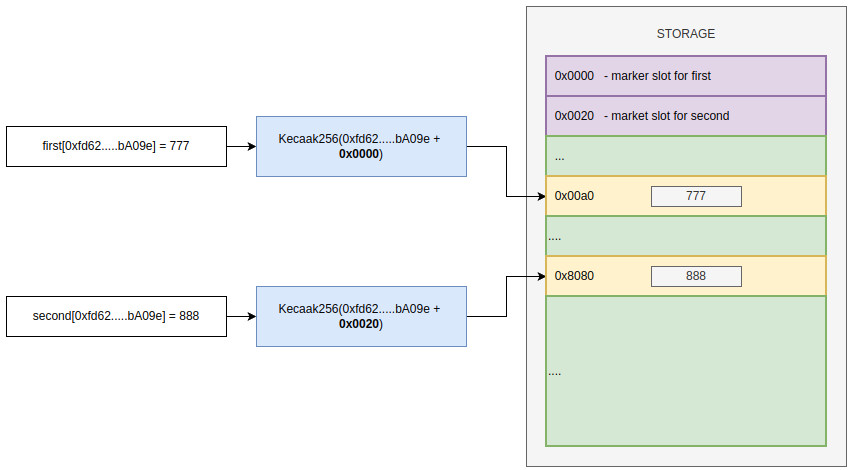
Итак, в теории все понятно. Давайте теперь разберемся с практикой.
Работа с маппингом на практике
Мы уже знаем, что для инициализации пустого маппинга нам ничего не нужно, кроме как запомнить адрес marker слота в storage. Пусть этот слот будет — 0x0.
Прежде чем разобраться с чтением, нам нужно что-то записать.
Помните, в первой статье мы говорили, о том, что первые четыре слота в памяти зарезервированы. (ссылка на документацию) Мы уже знаем для чего третий слот — это указатель на свободную память. А теперь узнаем, для чего первые два слота! Слоты с 0 по 0x20 и c 0x20 по 0x40 используются для работы с инструкциями хэширования. Туда записываются данные для хэширования.
Запись в маппинг
- Загружаем в память по адресу 0x0 (область для работы с хэшированием) ключ 0xdac17f958d2ee523a2206206994597c13d831ec7:
123PUSH20 0xdac17f958d2ee523a2206206994597c13d831ec7PUSH0MSTORE - Загружаем во второй слот 0x20 адрес слота-маркера в storage. У нас он 0x0. Поэтому записываем по адресу 0x20 значение нашего слота 0x0.
123PUSH0PUSH0x20MSTORE - Выполняем хэширование
1KECCAK256
Теперь хэш находятся на стэке. - Записываем данные. Хэш находится на вершине стэка. Осталось положить в стэк значение. Затем поменять местами с хэшом, поскольку для команды SSTORE на верхушке стэка должен быть адрес — куда писать. А второе значение в стэке — что записать.
123PUSH2 0x0309SWAP1SSTORE
Все. Данные записаны в маппинг. Приступаем к чтению.
Чтение из маппинга
Сначала нам нужно вычислить адрес, откуда будем читать. Код будет ровно таким же, как и в предыдущем пункте:
|
1 2 3 4 5 6 7 |
PUSH20 0xdac17f958d2ee523a2206206994597c13d831ec7 PUSH0 MSTORE PUSH0 PUSH0x20 MSTORE KECCAK256 |
Теперь на стэке у нас есть хэш — адрес слота. Осталось только прочитать данные по этому адресу из storage в стэк.
|
1 |
SLOAD |
Все. Теперь в стэке прочитанное значение.
Резюме
Мы разобрали, как хранятся данные маппинга в storage. Как их записывать и как читать. Мы взяли самый простой вариант с примитивными типами. С динамическими типами работа с маппингами будет немного сложнее. Однако, общий принцип тот же.
Предыдущая статья. Следующая статья.
Полный список статей по теме тут.
Заходите в наш телеграмм канал — Blockchain Witnesses! Делитесь опытом или задавайте вопросы, если что-то непонятно.
