В предыдущей статье мы разобрали загрузку пустого смарт-контракт в блокчейн. Мы узнали, что компиляторы контрактов достаточно глупые и преобразуют команды solidiy в готовые блоки. Из-за этого контракты порой содержат лишние инструкции. Давайте попробуем оптимизировать наш контракт. Но есть одна проблема. Как мы узнаем, что после наших оптимизаций контракт работает. Ведь пустой контракт ничего не делал. Если он будет неисправен, то он тоже ничего не будет делать.
Давайте добавим в наш смарт-контракт публичное поле типа uint. Тогда если после всех оптимизаций контракт вернет нам пустой поле, то будем считать, что наши оптимизации не сломали контракт. А заодно и узнаем, как в байткоде создаются поля.
Предыдущая статья. Следующая статья.
Полный список статей по теме тут.
Заходите в наш телеграмм канал — Blockchain Witnesses! Делитесь опытом или задавайте вопросы, если что-то непонятно.
Создаем и исследуем публичное поле
Давайте возьмем наш смарт контракт и добавим туда поле:
|
1 2 3 4 5 6 7 8 9 |
// SPDX-License-Identifier: GPL-3.0 pragma solidity ^0.8.25; contract BlockwitEmptyContract { uint public a = 777; } |
А теперь получим байткод (можно с помощью Remix, как в предыдущей статье).
|
1 2 |
60806040526103095f553480156013575f80fd5b5060ac80601f5f395ff3fe6080604052348015600e575f80fd5b50600436106026575f3560e01c80630dbe671f14602a575b5f80fd5b60306044565b604051603b9190605f565b60405180910390f35b5f5481565b5f819050919050565b6059816049565b82525050565b5f60208201905060705f8301846052565b9291505056fe a264697066735822122052b689f2eb123eb4fe4ead878d0b4a6224c0554c640c36015c4e5acc61d7c9d364736f6c63430008190033 |
Убираем метаданные (они у нас занимают — 106 символов в конце) и получаем чистый байткод:
60806040526103095f553480156013575f80fd5b5060ac80601f5f395ff3fe6080604052348015600e575f80f
d5b50600436106026575f3560e01c80630dbe671f14602a575b5f80fd5b60306044565b604051603b91906
05f565b60405180910390f35b5f5481565b5f819050919050565b6059816049565b82525050565b5f60208
201905060705f8301846052565b9291505056fe
Давайте теперь его скопируем в декомпилятор и посмотрим, что он выдаст:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 |
0000 60 PUSH1 0x80 0002 60 PUSH1 0x40 0004 52 MSTORE 0005 61 PUSH2 0008 5F PUSH0 0009 55 SSTORE 000A 34 CALLVALUE 000B 80 DUP1 000C 15 ISZERO 000D 60 PUSH1 0x13 000F 57 *JUMPI 0010 5F PUSH0 0011 80 DUP1 0012 FD *REVERT 0013 5B JUMPDEST 0014 50 POP 0015 60 PUSH1 0xac 0017 80 DUP1 0018 60 PUSH1 0x1f 001A 5F PUSH0 001B 39 CODECOPY 001C 5F PUSH0 001D F3 *RETURN 001E FE *ASSERT 001F 60 PUSH1 0x80 0021 60 PUSH1 0x40 0023 52 MSTORE 0024 34 CALLVALUE 0025 80 DUP1 0026 15 ISZERO 0027 60 PUSH1 0x0e 0029 57 *JUMPI 002A 5F PUSH0 002B 80 DUP1 002C FD *REVERT 002D 5B JUMPDEST 002E 50 POP 002F 60 PUSH1 0x04 0031 36 CALLDATASIZE 0032 10 LT 0033 60 PUSH1 0x26 0035 57 *JUMPI 0036 5F PUSH0 0037 35 CALLDATALOAD 0038 60 PUSH1 0xe0 003A 1C SHR 003B 80 DUP1 003C 63 PUSH4 0x0dbe671f 0041 14 EQ 0042 60 PUSH1 0x2a 0044 57 *JUMPI 0045 5B JUMPDEST 0046 5F PUSH0 0047 80 DUP1 0048 FD *REVERT 0049 5B JUMPDEST 004A 60 PUSH1 0x30 004C 60 PUSH1 0x44 004E 56 *JUMP 004F 5B JUMPDEST 0050 60 PUSH1 0x40 0052 51 MLOAD 0053 60 PUSH1 0x3b 0055 91 SWAP2 0056 90 SWAP1 0057 60 PUSH1 0x5f 0059 56 *JUMP 005A 5B JUMPDEST 005B 60 PUSH1 0x40 005D 51 MLOAD 005E 80 DUP1 005F 91 SWAP2 0060 03 SUB 0061 90 SWAP1 0062 F3 *RETURN 0063 5B JUMPDEST 0064 5F PUSH0 0065 54 SLOAD 0066 81 DUP2 0067 56 *JUMP 0068 5B JUMPDEST 0069 5F PUSH0 006A 81 DUP2 006B 90 SWAP1 006C 50 POP 006D 91 SWAP2 006E 90 SWAP1 006F 50 POP 0070 56 *JUMP 0071 5B JUMPDEST 0072 60 PUSH1 0x59 0074 81 DUP2 0075 60 PUSH1 0x49 0077 56 *JUMP 0078 5B JUMPDEST 0079 82 DUP3 007A 52 MSTORE 007B 50 POP 007C 50 POP 007D 56 *JUMP 007E 5B JUMPDEST 007F 5F PUSH0 0080 60 PUSH1 0x20 0082 82 DUP3 0083 01 ADD 0084 90 SWAP1 0085 50 POP 0086 60 PUSH1 0x70 0088 5F PUSH0 0089 83 DUP4 008A 01 ADD 008B 84 DUP5 008C 60 PUSH1 0x52 008E 56 *JUMP 008F 5B JUMPDEST 0090 92 SWAP3 0091 91 SWAP2 0092 50 POP 0093 50 POP 0094 56 *JUMP 0095 FE *ASSERT |
Давайте разбираться, что есть что.
Конструктор
Мы уже знакомы с этим участком кода. Это инициализация указателя на свободную память.
|
1 2 3 |
0000 60 PUSH1 0x80 0002 60 PUSH1 0x40 0004 52 MSTORE |
А дальше идет самое интересное — запись числа 777 в блокчейн. Storage как мы знаем — это и есть память блокчйена. А команда SSTORE как раз сохраняет значение в storage.
|
1 2 3 |
0005 61 PUSH2 0x0309 - если перевести из HEX то получим наше число 777 0008 5F PUSH0 0009 55 SSTORE - записывает uint256 в storage по адресу 0 |
Следующий блок мы также знаем из предыдущей статьи. Он проверяет передавался ли эфир при загрузке смарт-контракта. Если передавался, то выходим с ошибкой (ведь наш конструктор не payable). Если эфир не передавался, то прыгаем на 0x13.
|
1 2 3 4 5 6 7 8 |
000A 34 CALLVALUE 000B 80 DUP1 000C 15 ISZERO 000D 60 PUSH1 0x13 000F 57 *JUMPI 0010 5F PUSH0 0011 80 DUP1 0012 FD *REVERT |
Следующий участок кода нам также знаком. Он копирует эффективный код смарт-контракт. Т.е. код без конструктора и метаданные в память по адресу 0x0. Затем возвращает код с помощью RETURN. Таким образом код записывается в блокчейн.
|
1 2 3 4 5 6 7 8 9 10 |
0013 5B JUMPDEST 0014 50 POP 0015 60 PUSH1 0xac 0017 80 DUP1 0018 60 PUSH1 0x1f - адрес кода смарт-контракта без конструктора 001A 5F PUSH0 001B 39 CODECOPY 001C 5F PUSH0 001D F3 *RETURN 001E FE *ASSERT |
С конструктором мы разобрались. В нем все, что нам встречалось в предыдущей статье. Кроме блока, в котором записывается данные нашего поля a = 777 в блокчей:
|
1 2 3 |
0005 61 PUSH2 0x0309 - если перевести из HEX то получим наше число 777 0008 5F PUSH0 0009 55 SSTORE - записывает uint256 в storage по адресу 0 |
Давайте изучим код самого контракта.
Сам смарт-контракт
|
1 2 3 |
001F 60 PUSH1 0x80 0021 60 PUSH1 0x40 0023 52 MSTORE |
Первыми идут инструкции, котроые нам уже встречались. Это стандартная проверка на передачу эфира. Если эфир был передан, то в данном случае происходит выход по REVERT’у. Т.е. как обычно. Если эфир не был передан, то прыгаем на 0x0e.
|
1 2 3 4 5 6 7 8 |
0024 34 CALLVALUE 0025 80 DUP1 0026 15 ISZERO 0027 60 PUSH1 0x0e 0029 57 *JUMPI 002A 5F PUSH0 002B 80 DUP1 002C FD *REVERT |
Однако, как мы видим ниже, код уже идет с 002D. А 0x0e? Место куда мы должны были прыгнуть должно начинаться сильно раньше! Помните, мы копировали наш код в нулевой адрес, так вот — после копирования все адреса уменьшаться ровно на размер кода конструктора. Давайте поправим адреса — вычтем из них 0x24. Тогда байткод смарт-контракта без конструктора будет выглядеть так.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 |
0000 60 PUSH1 0x80 0002 60 PUSH1 0x40 0004 52 MSTORE 0005 34 CALLVALUE 0006 80 DUP1 0007 15 ISZERO 0008 60 PUSH1 0x0e 000A 57 JUMPI 000B 5F PUSH0 000C 80 DUP1 000D FD REVERT 000E 5B JUMPDEST 000F 50 POP 0010 60 PUSH1 0x04 0012 36 CALLDATASIZE 0013 10 LT 0014 60 PUSH1 0x26 0016 57 JUMPI 0017 5F PUSH0 0018 35 CALLDATALOAD 0019 60 PUSH1 0xe0 001B 1C SHR 001C 80 DUP1 001D 63 PUSH4 0x0dbe671f 0022 14 EQ 0023 60 PUSH1 0x2a 0025 57 JUMPI 0026 5B JUMPDEST 0027 5F PUSH0 0028 80 DUP1 0029 FD REVERT 002A 5B JUMPDEST 002B 60 PUSH1 0x30 002D 60 PUSH1 0x44 002F 56 JUMP 0030 5B JUMPDEST 0031 60 PUSH1 0x40 0033 51 MLOAD 0034 60 PUSH1 0x3b 0036 91 SWAP2 0037 90 SWAP1 0038 60 PUSH1 0x5f 003A 56 JUMP 003B 5B JUMPDEST 003C 60 PUSH1 0x40 003E 51 MLOAD 003F 80 DUP1 0040 91 SWAP2 0041 03 SUB 0042 90 SWAP1 0043 F3 RETURN 0044 5B JUMPDEST 0045 5F 5F 0046 54 SLOAD 0047 81 DUP2 0048 56 JUMP 0049 5B JUMPDEST 004A 5F PUSH0 004B 81 DUP2 004C 90 SWAP1 004D 50 POP 004E 91 SWAP2 004F 90 SWAP1 0050 50 POP 0051 56 JUMP 0052 5B JUMPDEST 0053 60 PUSH1 0x59 0055 81 DUP2 0056 60 PUSH1 0x49 0058 56 JUMP 0059 5B JUMPDEST 005A 82 DUP3 005B 52 MSTORE 005C 50 POP 005D 50 POP 005E 56 JUMP 005F 5B JUMPDEST 0060 5F 5F 0061 60 PUSH1 0x20 0063 82 DUP3 0064 01 ADD 0065 90 SWAP1 0066 50 POP 0067 60 PUSH1 0x70 0069 5F PUSH0 006A 83 DUP4 006B 01 ADD 006C 84 DUP5 006D 60 PUSH1 0x52 006F 56 JUMP 0070 5B JUMPDEST 0071 92 SWAP3 0072 91 SWAP2 0073 50 POP 0074 50 POP 0075 56 JUMP 0076 FE ASSERT |
Теперь посмотрим куда мы на самом деле прыгаем в 0x0e:
|
1 2 3 4 5 6 7 |
000E 5B JUMPDEST 000F 50 POP 0010 60 PUSH1 0x04 0012 36 CALLDATASIZE 0013 10 LT 0014 60 PUSH1 0x26 0016 57 JUMPI |
Этот код нам не встречался ранее. JUMPDEST понятно — так помечаются места, куда можно прыгать. Дальше POP — очистка стека. А вот дальше мы помещаем в стэк 0x04 и выполняем CALLDATASIZE. Эта инструкция помещает в стэк размер calldata из входящего сообщения. Что за входящее сообщение? Мы уже знаем из Solidity, что в функциях есть доступ к объекту msg. В котором хранится много чего полезного:
- msg.data — calldata — данные о том, какая функция вызывается у контракта и какие аргументы ей передаются.
- msg.sender — адрес того, кто вызывает функцию нашего контракта
- msg.sig — первые 4 байта calldata — т.е. идентификатор функции, которая вызывается у контракта
- msg.value — сколько wei передано при вызове контракта
Именно размер данных msg.data инструкция CALLDATASIZE помещает в стэк.
Дальше идет инструкция LT . Расшифровывается как Less than — меньше чем. Как можно догадаться, она сравнивает первое значение на стэке со вторым. А именно — если второе значение на стэке меньше первого , то в стэк помещается единица. Иначе в стэк помещается 0.
На стэке у нас сейчас 0x04 и msg.data.size. Если 4 > msg.data.size, то в стэк помещается единица.
Но что это значит ? 4-ка тут выбрана не случайно. В solidiy мы привыкли называть функции говорящими именами. Машине все эти имена не нужны и могут занимать много места. Поэтому в байткоде принято вместо имен указывать 4-байтовый идентификатор функции (на самом деле это 4 байта от хэша kecaak256 от объявления функции). В этом участке кода сравнивают размер msg.data.size с размером идентификатора функции. Если размер меньше 4, то это точно не вызов функции. Таким образом это сравнение определяет — является ли вызов смарт-контракта вызовом функции или нет.
Дальше понятно, если вызов смарта не является вызовом функции то переходим на 0x26. А что у нас в 0x26 ?
|
1 2 3 4 |
0026 5B JUMPDEST 0027 5F PUSH0 0028 80 DUP1 0029 FD REVERT |
Тут у нас знакомая конструкция — REVERT, которая возвращает ноль байт с нулевого адреса. Т.е. просто выход из смарт-контракта с отменой изменений.
Вернемся тогда к ветке, в которой вызов нашего контракта является вызовом функции. А там видим вот что:
|
1 2 3 4 5 |
0017 5F PUSH0 0018 35 CALLDATALOAD 0019 60 PUSH1 0xe0 001B 1C SHR 001C 80 DUP1 |
CALLDATALOAD — читает 32 байта начиная с адреса, который в стэке. Прочитанные данные помещает в стэк. У нас в стэке 0. Поэтому будут прочитаны 32 байта с начала msg.data.
SHR — shift right — сдвиг в право — инструкция, которая сдвигает первый аргумент в стэке на кол-во равное второму аргументу в стэке. В нашем случае в стэке первым аргументом лежат 32 байта от msg.data. А вторым агрументом мы положили 0xe0. Зачем такой сдвиг нужен?
- 32 байта = 32*8 = 256 бит
- 0xe0 = 224
- если мы сдвинем 256 бит на 224 бита вправо, то получим 256 — 224 = 32 бита. А 32 бита / 8 = 4 байта.
Давайте посмотрим на примере как это работает. Пусть наши 32 байта — это:
201905060705f8301846052565b9291505056fe0910390f35b5f5534801560d0
Сдвинув в право мы получим такое значение.
000000000000000000000000000000000000000000000000000000020190506
Т.е. 32 байта сдвигаются вправо, чтобы получить 4 байта. А 4 байта — это ничто иное как размер идентификатора функции. Т.е. этим сдвигом мы выделяем идентификатор функции.
Далее выполняется команда дублирования значения стэка DUP1. Зачем это сделано, станет ясно позже. Пока запомним, что в стэке у нас два 4-байтного идентификатора функции.
Дальше мы видим такой код
|
1 2 3 4 |
001D 63 PUSH4 0x0dbe671f 0022 14 EQ 0023 60 PUSH1 0x2a 0025 57 JUMPI |
В стэк помещается 4-байтовый идентификатор. Выполняется команда сравнения EQ. Equals — равно. Если два последних значения в стэке равны, то в стэк помещается единица. Прыгаем на 0x2a, если в стэке единица. Т.е. тут происходит сравнение идентификатора функции из msg.data — т.е. функции, которая была вызвана с идентификатором функции 0x0dbe671f. Если идентификаторы совпадают, то мы идем на 0x2a.
Давайте пока оставим этот прыжок на время и посмотрим, что будет если идентификаторы не совпадут. Дальше идет участок кода:
|
1 2 3 4 |
0026 5B JUMPDEST 0027 5F PUSH0 0028 80 DUP1 0029 FD REVERT |
Т.е. просто происходит выход из контракта с отменой всех изменений.
Теперь вернемся к нашему сравнению идентификатора вызываемой функции с 0x0dbe671f. Что же это такое? Давайте возьмем какой-нибудь онлайн тул для получения значения kecaak-256. Например, вот этот. И введем в него «a()». Тогда мы получим следующую картину:
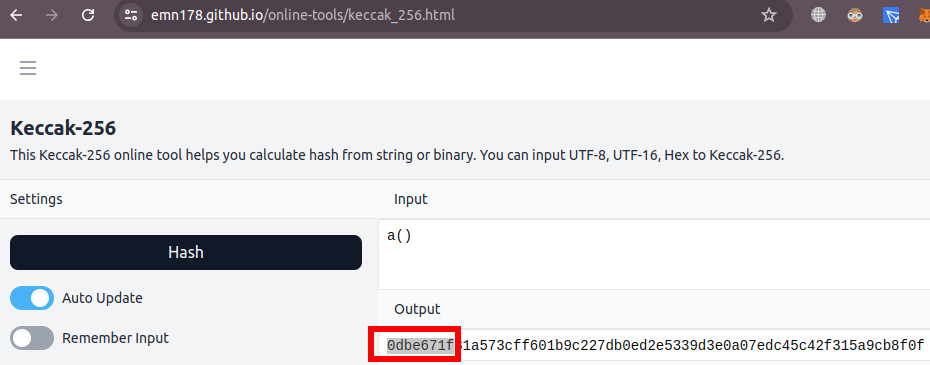
Первые четыре байта полученного значения — это наши искомые 0dbe671f. Выходит, что это идентификатор функции a(). А что это за функция такая? Мы же никакие функции не писали в контракте. Давайте вспомни, как называется наше поле, которому мы присвоили 777. Правильно! Его имя a. И объявлено это поле публичным, для того, чтобы можно было его удобно прочитать.
|
1 |
uint public a = 777; |
Компилятор Soldity для публичных полей автоматически генерирует функцию для чтения. И имя этой функции совпадает с именем поля.
Вот откуда взялось это сравнение. Это сравнение определяет какая функция в контракте была вызвана. И если вызвана функция a(), то прыгаем на код этой функции. Мы его разберем чуть позже.
Помните что перед сравнением идентификатор вызванной функции дублировался на стэке?
|
1 2 3 4 5 6 7 8 9 10 |
001C 80 DUP1 <- дублирование идентификатора вызываемой функции 001D 63 PUSH4 0x0dbe671f 0022 14 EQ 0023 60 PUSH1 0x2a 0025 57 JUMPI 0026 5B JUMPDEST 0027 5F PUSH0 0028 80 DUP1 0029 FD REVERT |
Посмотрим внимательно на этот код. Если сравнение не проходит, то задублированное значение в стэке нигде не используется. Забегая вперед скажу — это задублированное значение не используется и при переходе на 0x2a. Так зачем это дублирование?
Как я и говорил ранее компилятор глупый. Генерирует код шаблонами. Это дублирование имело бы смыл, если бы у нас было несколько функций и несколько сравнений. А несколько сравнений — это несколько участков кода с 1с по 25. Давайте представим, что у нас три сравнения.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
... 80 DUP1 63 PUSH4 0x0dbe671f 14 EQ 60 PUSH1 0x2a 57 JUMPI 80 DUP1 63 PUSH4 0xafe98897 14 EQ 60 PUSH1 0xca 57 JUMPI 80 DUP1 63 PUSH4 0x90756df6 14 EQ 60 PUSH1 0xfa 57 JUMPI ... |
Каждая операция cравнения забирает со стэка два аргумента! Один из которых идентификатор вызываемой функции. Именно поэтому и нужно дублирование, что к следующему сравнению в стэке остался идентификатор вызываемой функции. Мы видим, что все три участка кода — шаблонны! Скорее всего компилятор берет шаблон и генерирует код для любого кол-ва сравнений. Хоть для одного, хоть для ста. Но мы то с Вами видим, что наш код с вызовом одной функции можно оптимизировать, убрав инструкцию DUP1. Тем самым мы сэкономим 3 единицы газа!
Код функции
А теперь давайте вернемся к нашей функции a(). Мы дошли до прыжка по адресу 0x2a. По этому адресу расположен код нашей функции. Давайте посмотрим на этот код:
|
1 2 3 4 |
002A 5B JUMPDEST 002B 60 PUSH1 0x30 002D 60 PUSH1 0x44 002F 56 JUMP |
Тут пока ничего интересного не происходит. В стэк помещается два значения. Очевидно будет прыжок по адресу 0x44 при этом стэке останется 0x30. Давайте посмотрим на 0x44:
|
1 2 3 4 5 |
0044 5B JUMPDEST 0045 5F PUSH0 0046 54 SLOAD 0047 81 DUP2 0048 56 JUMP |
Инструкция SLOAD читает 32-байтное значение по адресу 0 (который мы положили в стэк командой PUSH0) из storage и помещает в стэк. А что у нас расположено по нулевому адресу в storage? Давайте вспомним код из конструктора:
|
1 2 3 |
0005 61 PUSH2 0x0309 - если перевести из HEX то получим наше число 777 0008 5F PUSH0 0009 55 SSTORE - записывает uint256 в storage по адресу 0 |
Правильно — в конструкторе мы загрузили в storgae по адресу 0 значение 777. Т.е. это есть значение нашего поля a.
Далее мы видим интересную инструкцию DUP2. Она дублирует последнее второе значение на стэке. А последнее второе значение у нас 0x30. Помните мы перед прыжком на 0x44 помещали в стэк 0x30 — вот это оно и есть. Поэтому дальше мы прыгаем на 0x30. Когда мы перейдем на 0x30 то в стэке у нас будет значение поля a = 777.
Судя по прыжку на этот участок кода — он, вероятно, тоже какой-то шаблонный и сделан для чтения переменных в стэк. Но пока это только догадка.
Давайте посмотрим на 0x30:
|
1 2 3 4 5 6 7 8 |
0030 5B JUMPDEST 0031 60 PUSH1 0x40 0033 51 MLOAD 0034 60 PUSH1 0x3b 0036 91 SWAP2 0037 90 SWAP1 0038 60 PUSH1 0x5f 003A 56 JUMP |
Тут мы видим чтение MLOAD в стэк указателя на участок свободной памяти (мы помним, что этот указатель находится всегда по адресу 0x40 в памяти). Далее в стэк помещается 0x3b. Теперь в стэке у нас такие данные:
- 0x3b
- указатель на свободную память — 0x80
- значение переменной a = 777
- 0x30
Далее идет не знакомые ранее нам две операции SWAP2 и SWAP1. SWAP2 — меняет местами первый и третий элементы стэка, а SWAP1 первый и второй. После выполнения этих операций стэк будет выглядеть так:
- указатель на свободную память — 0x80
- значение переменной a = 777
- 0x3b
- 0x30
Далее мы прыгаем на 0x5f. Далее я будут приводить участки кода и состояние стэка после них. Не все из участков понятны для чего они. Многие из них скорее всего шаблонный код и имеет смысл, если у нас много функций в контракте. Но сейчас наша задача понять, что реально полезного делает функция. И что является результатом работы кода. Вы можете потренироваться и после каждого участка кода попробовать написать как будет меняться стэк.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
005F 5B JUMPDEST 0060 5F PUSH0 0061 60 PUSH1 0x20 0063 82 DUP3 0064 01 ADD 0065 90 SWAP1 0066 50 POP 0067 60 PUSH1 0x70 0069 5F PUSH0 006A 83 DUP4 006B 01 ADD 006C 84 DUP5 006D 60 PUSH1 0x52 006F 56 JUMP |
После выполнения этого кода стэк будет выглядеть так:
- значение переменной a = 777
- 0x80
- 0x70
- 0xa0
- 0x80
- значение переменной a = 777
- 0x3b
- 0x30
Тут стоит пояснить, что скорее всего добавление 0x20 к 0x80 — это получение указателя на следующую свободную ячейку памяти. Мы помним, что EVM оперирует 32 байтными значениями. А 32 — это 0x20.
|
1 2 3 4 5 |
0052 5B JUMPDEST 0053 60 PUSH1 0x59 0055 81 DUP2 0056 60 PUSH1 0x49 0058 56 JUMP |
После выполнения этого кода стэк будет таким:
- значение переменной a = 777
- 0x59
- значение переменной a = 777
- 0x80
- 0x70
- 0xa0
- 0x80
- значение переменной a = 777
- 0x3b
- 0x30
|
1 2 3 4 5 6 7 8 9 |
0049 5B JUMPDEST 004A 5F PUSH0 004B 81 DUP2 004C 90 SWAP1 004D 50 POP 004E 91 SWAP2 004F 90 SWAP1 0050 50 POP 0051 56 JUMP |
После выполнения этого участка кода стэк станет таким.
- значение переменной a = 777
- значение переменной a = 777
- 0x80
- 0x70
- 0xa0
- 0x80
- значение переменной a = 777
- 0x3b
- 0x30
|
1 2 3 4 5 6 |
0059 5B JUMPDEST 005A 82 DUP3 005B 52 MSTORE 005C 50 POP 005D 50 POP 005E 56 JUMP |
А этот участок кода нам важен. Тут присутствует команда MSTORE. И если Вы следили за стэком. То MSTORE запишет в память по адресу 0x80 наше значение 777. А прыжок будет выполнен на адрес 0x70. После чего стэк будет выглядеть так:
- 0xa0
- 0x80
- значение переменной a = 777
- 0x3b
- 0x30
Прыгаем на 0x70
|
1 2 3 4 5 6 7 |
0070 5B JUMPDEST 0071 92 SWAP3 0072 91 SWAP2 0073 50 POP 0074 50 POP 0075 56 JUMP 0076 FE ASSERT |
После выполнения этого участка кода стэк станет таким:
- 0xa0
- 0x30
Прыгаем на 0x3b:
|
1 2 3 4 5 6 7 8 |
003B 5B JUMPDEST 003C 60 PUSH1 0x40 003E 51 MLOAD 003F 80 DUP1 0040 91 SWAP2 0041 03 SUB 0042 90 SWAP1 0043 F3 RETURN |
Вот он — наш выход и программы. И перед RETURN у нас стэк будет выглядеть так:
- 0x80
- 0x20
- 0x30
Нас интересуют первые два значения. RETURN их будет воспринимать как адрес в памяти из которого возвращаем значение и 0x20 — как размер возвращаемого значения. Т.е. возвращаются 32 байта из памяти по адресу 0x80. А что у нас по адресу 0x80 ? Несколько шагов назад мы туда из storage загрузили значение нашего поля a = 777. Вот мы и нашли эффективный код нашей функции.
Таким образом, если отбросить все пока не эффективные пока для нас блоки, то код функции делает следующее:
- Загружает из storage значение поля «a» в стэк
- Записывает значение из стэка в память по адресу указателя свободной памяти.
- Возвращает из памяти значение.
Но зачем же все эти промежуточные действия? Смысл в них есть. И, порой этот смысл проявляется, когда контракт содержит несколько разных функций. Тогда имеет смысл выделять общий блоки, чтобы не дублировать их в каждой функции. Например, блоки чтения из storage. Но в нашей одной функции большинство этих действий лишние. Поэтому, мы смело можем оптимизировать наш контракт. Что мы из сделаем в следующей статье.
А пока давайте подведем итоги, что нового мы узнали.
Резюме
Мы разобрали контракт с одним полем. Посмотрели, как в конструкторе поля записываются в storage — память блокчейна.
Мы узнали, что для публичных полей компилятор solidiy создает одноименную функцию чтения.
Мы также узнали, что в контракте есть селектор функций — блок, в котором идентификатор вызываемой функции из транзакции сравнивается с идентификаторами функций в контракте.
Теперь мы знаем, что условно наш что смарт-контракт состоит из следующих блоков:

Теперь у нас все готово, чтобы попробовать оптимизировать наш смарт-контракт. Чем в следующей статье мы и займемся.
Предыдущая статья. Следующая статья.
Полный список статей по теме тут.
Заходите в наш телеграмм канал — Blockchain Witnesses! Делитесь опытом или задавайте вопросы, если что-то непонятно.
